Nilalaman
- Kahulugan - Ano ang ibig sabihin ng Web Crawler?
- Isang Panimula sa Microsoft Azure at ang Microsoft Cloud | Sa buong gabay na ito, malalaman mo kung ano ang lahat ng cloud computing at kung paano makakatulong ang Microsoft Azure sa iyo upang lumipat at patakbuhin ang iyong negosyo mula sa ulap.
- Ipinaliwanag ng Techopedia ang Web Crawler
Kahulugan - Ano ang ibig sabihin ng Web Crawler?
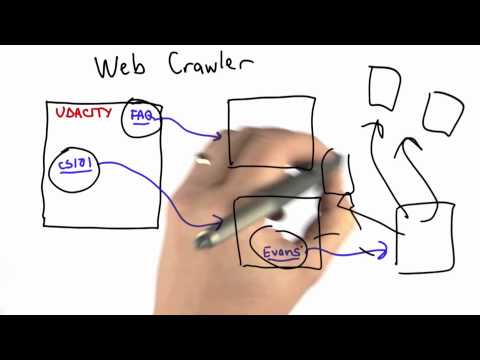
Ang isang Web crawler ay isang bot ng Internet na tumutulong sa pag-index ng Web. Gumapang sila ng isang pahina nang sabay-sabay sa pamamagitan ng isang website hanggang sa na-index ang lahat ng mga pahina. Tumutulong ang mga web crawler sa pagkolekta ng impormasyon tungkol sa isang website at ang mga link na nauugnay sa kanila, at makakatulong din sa pagpapatunay ng HTML code at mga hyperlink.
Ang isang Web crawler ay kilala rin bilang isang Web spider, awtomatikong index o simpleng mag-crawl.
Isang Panimula sa Microsoft Azure at ang Microsoft Cloud | Sa buong gabay na ito, malalaman mo kung ano ang lahat ng cloud computing at kung paano makakatulong ang Microsoft Azure sa iyo upang lumipat at patakbuhin ang iyong negosyo mula sa ulap.
Ipinaliwanag ng Techopedia ang Web Crawler
Kinokolekta ng mga web crawler ang impormasyon tulad ng URL ng website, impormasyon ng meta tag, nilalaman ng Web page, ang mga link sa webpage at ang mga patutunguhan na humahantong mula sa mga link na iyon, pamagat ng web page at anumang iba pang nauugnay na impormasyon. Sinusubaybayan nila ang mga URL na na-download upang maiwasan ang muling pag-download ng parehong pahina. Ang isang kumbinasyon ng mga patakaran tulad ng muling pagbisita sa patakaran, patakaran sa pagpili, paralelisasyon ng patakaran at patakaran ng pagiging mabibigyan ang tumutukoy sa pag-uugali ng Web crawler. Maraming mga hamon para sa mga web crawler, lalo na ang malaki at patuloy na umuusbong na World Wide Web, tradeoff ng pagpili ng nilalaman, mga obligasyong panlipunan at pakikitungo sa mga kalaban.
Ang mga web crawler ay ang mga pangunahing sangkap ng mga search engine ng Web at mga system na tumingin sa mga web page. Tumutulong sila sa pag-index ng mga entry sa Web at pinapayagan ang mga gumagamit sa mga query laban sa index at nagbibigay din ng mga webpage na tumutugma sa mga query. Ang isa pang paggamit ng mga Web crawler ay nasa Web archive, na nagsasangkot ng malalaking hanay ng mga webpage na pana-panahong nakolekta at nai-archive. Ginagamit din ang mga web crawler sa pagmimina ng data, kung saan nasuri ang mga pahina para sa iba't ibang mga pag-aari tulad ng mga istatistika, at pagkatapos ay isinasagawa ang mga analytics ng data.