
Nilalaman

Pinagmulan: Kran77 / Dreamstime.com
Takeaway:
Ang mga malalim na modelo ng pag-aaral ay nagtuturo ng mga computer upang mag-isip ng kanilang sarili, na may ilang masayang at kawili-wiling mga resulta.
Ang malalim na pag-aaral ay inilalapat sa higit pa at higit pang mga domain at industriya. Mula sa mga walang driver na kotse, sa paglalaro ng Go, sa pagbuo ng musika ng mga imahe, may mga bagong malalim na modelo ng pag-aaral na lumalabas araw-araw. Narito pupunta kami sa maraming mga tanyag na modelo ng malalim na pag-aaral. Kinukuha ng mga siyentipiko at developer ang mga modelong ito at binabago ang mga ito sa bago at malikhaing paraan. Inaasahan namin na ang showcase na ito ay maaaring magbigay ng inspirasyon sa iyo upang makita kung ano ang posible. (Upang malaman ang tungkol sa pagsulong sa artipisyal na katalinuhan, tingnan ang Magagawa ba ng mga Computer na Maipakita ang Human Brain?)
Estilo ng Neural
Hindi mo maaaring mapabuti ang iyong mga kasanayan sa pag-programming kapag walang nagmamalasakit sa kalidad ng software.
Tagapagsalaysay ng Neural

Ang Neural Storyteller ay isang modelo na, kapag binigyan ng isang imahe, ay maaaring makabuo ng isang pag-iibigan tungkol sa imahe. Ito ay isang nakakatuwang laruan at maaari mong isipin ang hinaharap at makita ang direksyon kung saan gumagalaw ang lahat ng mga artipisyal na modelo ng katalinuhan na ito.

Ang function sa itaas ay ang "style-shift" na operasyon na nagpapahintulot sa modelo na maglipat ng mga standard na caption ng imahe sa estilo ng mga kwento mula sa mga nobela. Ang estilo ng paglilipat ay inspirasyon ng "Isang Neural Algorithm ng Artistic Style."
Data
Mayroong dalawang pangunahing mapagkukunan ng data na ginagamit sa modelong ito. Ang MSCOCO ay isang dataset mula sa Microsoft na naglalaman ng halos 300,000 mga imahe, na may bawat imahe na naglalaman ng limang mga caption. Ang MSCOCO lamang ang pinangangasiwaan na data na ginagamit, nangangahulugang ito lamang ang data kung saan ang mga tao ay kailangang pumasok at tahasang magsulat ng mga kapsyon para sa bawat imahe.
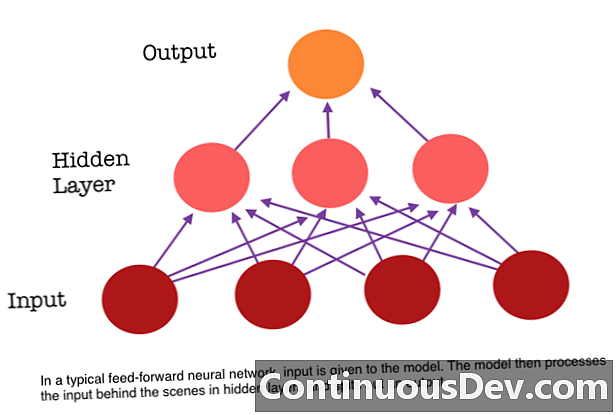
Ang isa sa mga pangunahing limitasyon ng isang feed-forward na neural network ay wala itong memorya. Ang bawat hula ay independyente mula sa mga nakaraang kalkulasyon, na kung ito ang una at tanging hula lamang ng network na ginawa. Ngunit para sa maraming mga gawain, tulad ng pagsasalin ng isang pangungusap o talata, ang mga input ay dapat na binubuo ng sunud-sunod at magkakaugnay na data. Halimbawa, mahirap na magkaroon ng kahulugan ang isang solong salita sa isang pangungusap nang walang ibinigay na con ng mga nakapalibot na salita.
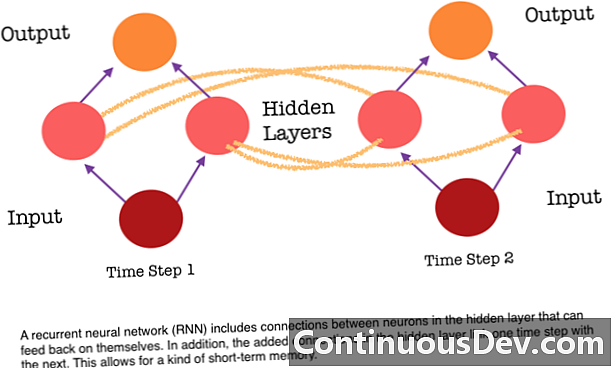
Ang mga RNN ay naiiba dahil nagdagdag sila ng isa pang hanay ng mga koneksyon sa pagitan ng mga neuron. Pinapayagan ng mga link na ito ang mga pag-activate mula sa mga neuron sa isang nakatagong layer upang muling ibalik sa kanilang sarili sa susunod na hakbang sa pagkakasunud-sunod. Sa madaling salita, sa bawat hakbang, ang isang nakatagong layer ay tumatanggap ng parehong pag-activate mula sa layer sa ibaba nito at din mula sa nakaraang hakbang sa pagkakasunud-sunod. Ang istraktura na ito ay mahalagang nagbibigay ng paulit-ulit na memorya ng mga network ng neural. Kaya para sa gawain ng pagtuklas ng bagay, ang isang RNN ay maaaring gumuhit sa mga nakaraang pag-uuri ng mga aso upang makatulong na matukoy kung ang kasalukuyang imahe ay isang aso.
Char-RNN TED
Ang kakayahang umangkop na istraktura na ito sa nakatagong layer ay nagpapahintulot sa mga RNN na maging napakahusay para sa mga modelo ng wika na antas ng character. Ang Char RNN, na orihinal na nilikha ni Andrej Karpathy, ay isang modelo na tumatagal ng isang file bilang input at sinasanay ang isang RNN upang malaman upang mahulaan ang susunod na karakter sa isang pagkakasunud-sunod. Ang RNN ay maaaring makabuo ng character sa pamamagitan ng character na magiging hitsura ng orihinal na data ng pagsasanay. Ang isang demo ay sinanay gamit ang mga transcript ng iba't ibang mga TED Talks. Pakanin ang modelo ng isa o maraming mga keyword at bubuo ito ng isang sipi tungkol sa mga (mga) keyword sa boses / istilo ng isang TED Talk.
Konklusyon
Ang mga modelong ito ay nagpapakita ng mga bagong breakthrough sa machine intelligence na naging posible dahil sa malalim na pagkatuto. Ipinapakita ng malalim na pag-aaral na maaari nating malutas ang mga problema na hindi natin kailanman malulutas, at hindi pa natin nakarating ang talampas na iyon. Asahan na makita ang maraming mga kapana-panabik na mga bagay tulad ng mga walang driver na kotse sa susunod na ilang taon bilang isang resulta ng malalim na pagbabago sa pag-aaral.